
Blog - Sunset Days
No, this is not about at which time the sun sets. It will set soon enough. No, this is about the world, about economics, politics, software, technology, and everything.
I saw a grafitti once on a rust-brown railway bridge, defiantly announcing in large, bright letters: "Sunrise people, sunset days", actually a quote from a song of the band Standstill. This was 2016. And while various social movements of all times harboured a gloomy view of their respective present, recent political events added an alarming sense of actuality to those letters. Sunset days indeed. Let us all be sunrise people (well, not literally perhaps); let us work towards a new dawn.
April 29 2024 20:18:27.
GENED 2024 in Chemnitz
The 10th annual meeting of the GENED (German Network for New Economic Dynamics) will take place in Chemnitz this year (September 30 to October 2). This is not just an anniversary for GENED (the 10th annual meeting), but also the first time it is held in former East Germany, certainly an area with its very own and interesting, though not always favorable economic dynamics. This is not all; participants will also get to see Chemnitz, which is due to be European cultural capital in 2025, just 3 months after the GENED meeting. The participants will, of course, have some time to enjoy Chemnitz; you could thing of it as a sneak peak at the future European cultural capital.
GENED is the most important association of economists working on economic dynamics. In a very broad sense, that is the development and application of computational models of economic dynamics based on interacting heterogeneous agents, including empirical contributions and applications of new methods in the context of economic dynamics. This is a very exciting and dynamic - pun intended - field of economics. I am very pleased to have the meeting in Chemnitz this year and am looking forward to many interesting talks, including the tutorial on complexity economics by Jean-Philippe Bouchaud.
You can find all the details on the website, here. Submission is via email to gened2024 wiwi.tu-chemnitz.de until August 1st.
wiwi.tu-chemnitz.de until August 1st.
April 07 2024 10:29:25.
EAEPE 2024 Research Area [Q] call for papers - New entanglements: Changing technology and its impact on supply chains, finance, innovation, and the economy as a whole
The call for Research Area [Q]'s complexity sessions at this year's EAEPE conference in Bilbao, Spain, (Sep 4-6) is out. While one focus is - fittingly - on new technologies like AI messing with the traditional organization of the economy, all other submissions on complex systems in economics and on the economy as a highly interconnected complex system are, as always, also highly welcome.
Please see the call here. The submission deadline, which may or may not be extended, is this Friday, Apr 12; submissions here.
September 14 2023 13:08:21.
EAEPE 2023 in Leeds - Research Area [Q] sessions
Yesterday marked the start of the EAEPE conference 2023 in Leeds with an entertaining, though perhaps contentious keynote on the future AI by Paul Nightingale. It was more history of thought than innovation economics, but it was certainly isightful.
Research Area [Q] (Complexity Economics) will have eleven papers in three sessions this year - more than ever before. The first session will be this afternoon, the other two tomorrow. I'm very much looking forward to it; there are many exciting and interesting talks. All the talks will be streamed online using BB Collab, like in previous years.The detailed program is as follows:
| 16:30-18:30 | Sep. 14 2023 | Session Q1 Complexity Economics 1 | Technological and Economic Change in Complex Economic Systems |
| 16.30 | Kerstin Hötte, Johannes Lumma, Francois Lafond, Vasco Carvalho, Victor Meirinhos | Alan Turing Institute & University of Oxford, UK | Input-output analysis using large-scale payments data (Abstract) |
| 17.00 | Jan Weber | University Duisburg-Essen | Asymmetric Perception of Firm Entry and Exit Dynamics (Paper) |
| 17.30 | Sabin Roman, Francesco Bertolotti | University of Cambridge, UK | Inducing global sustainability in a network of unstable socio-ecological systems (Abstract) |
| Session Link | Room: SR2.10 |
| 9:00-11:00 | Sept. 15 2023 | Session Q2 Complexity Economics 2 | The Economic Complexity Paradigm and its Application |
| 9.00 | Danielle Evelyn De Carvalho, Alexandre De Queiroz Stein, Arthur Ribeiro Queiroz, João Prates Romero, Ana Maria Hermeto Camilo De Oliveira | Universidade Federal de Minas Gerais, Brazil | Economic Complexity and Per Capita GDP Growth: a Differences-In-Differences Analysis for Brazilian Municipalities(Paper) |
| 9.30 | Joao Romero, Camila Gramkow, Guilherme Magacho | Universidade Federal de Minas Gerais, Brazil | Economic Complexity and Green Technology Absorption (Abstract) |
| 10.00 | Fabricio Silveira, João Prates Romero, Elton Freitas, Gustavo Britto, Romulo Paes-Sousa | Fiocruz & Universidade Federal de Minas Gerais, Brazil | Mapping the Sustainable Development: A Network-Based Approach for Achieving the SDGs (Paper) |
| 10.30 | Gustavo Britto, Alexandre De Queiroz Stein | Universidade Federal de Minas Gerais, Brazil | An Economic Complexity Approach for Structural Heterogeneity in Brazilian Agricultural Sector (Paper) |
| Session Link | Room: SR2.09 |
| 14:30-16:30 | Sept. 15 2023 | Session Q3 Complexity Economics 3 | Inequality in Complex Economic Systems |
| 14.30 | Gilberto Dias Paião Junior, Diogo Ferraz | Sao Paulo State University, Brazil | Export Diversification and Economic Growth: A Systematic Literature Review (Abstract) |
| 15.00 | Daniel Mayerhoffer, Jan Schulz | University of Amsterdam, Netherlands & Frankfurt School of Finance and Management, Germany | Social Segregation, Misperceptions, and Emergent Redistribution (Paper) |
| 15.30 | Jonas Schulte | University Duisburg-Essen | Unraveling the Ergodic Assumption: Implications for Wealth and Income Inequality in Advanced Economies (Abstract) |
| 16.00 | Rafael Wildauer, Ines Heck, Jakob Kapeller | University of Greenwich | Was Pareto Right? Is the Distribution of Wealth Thick-Tailed? (Abstract) |
| Session Link | Room: SR2.09 |
Please note that there was a small change in sessions Q2 and Q3; we moved the paper by Gilberto Dias Paião Junior and Diogo Ferraz to Q3, so we have 4 papers in both sessions now and enough time for all speakers.
March 27 2023 17:53:43.
EAEPE 2023 Research Area [Q] call for papers - Golden chains in the interconnected economy
The deadline for submissions for the EAEPE conference in Leeds this year (Sep 13-15) is coming up again. Research Area [Q] - Economic Complexity will focus on connections this year, golden chains, supply chains, bankruptcy cascades, chains of accountability. RA [Q]'s call for abstracts is online here. The submission deadline, which may or may not be extended, is this Friday, Mar 31; submissions here.
November 07 2022 02:31:12.
Twitter in turmoil
Within a week of purchasing Twitter Inc. for 44 billion dollars, Elon Musk has done his very best to put the wrecking ball to the company. Reliable infrastructure, permissive policy, and the network externalities generated by the giant user base have made Twitter the single most important micro-blogging platform - not just for researchers but for society at large. But with the new CEO, things are about to change.
Will he succeed in making a profit with this deal? Hard to say. He payed significantly more than the market valuation. Does he care? Probably not, no matter what he might say. Why did he buy it then? Well, that he has lofty ambitions, the kind that can be furthered by owning Twitter, is not in doubt - different from his understanding of this technology. While he is often seen as a technological visionary, there is little evidence that he actually understands any of the technologies developed by the companies he owns. He mostly keeps the media's attention with well-curated PR-stunts, by insulting people, by peddling conspiracy theories (usually "as a joke"), and with highly publicized but often questionable predictions.
It is easy to see that absolute control of Twitter will allow him to do this much better. It may also facilitate pursuing political ambitions. Besides frequently hosting political and personal dogfights, Twitter is also the platform most widely used for science communication, discussing new technologies, and possibly also attracting investment in new technologies. Musk's first actions as CEO include (1) firing half the employees with little notice, including in the teams tasked with combating misinformation and protecting human rights, (2) turning important features such as the blue checkmark (indicating verified and notable accounts) into empty shells, and attempting to monetize various features. Back in April, he also ominously said that he would somehow strengthen free speech on Twitter in a way that doesn't actually strengthen free speech, so all kinds of fundamentalists, conspiracy people, neo-nazis, and sycophants are now hoping to have their banned accounts restored soon. Both advertisers, managers, and regular, respectable Twitter users are taking flight - unsurprisingly.
While it as been pointed out early on (and here) that it is dangerous to have such a socially important platform controlled by just one company, whose interests may not be aligned with those of society, Twitter's (Jack Dorsey's) visionary recognition of the potential of microblogging merit admiration. Twitter really shaped the very idea of micro-blogging - "tweeting". Distributed alternatives such as Mastodon only emerged later. And then, they were simply too small to gain the necessary momentum. This is still true - especially if your carreer depends on it, as it does for many researchers. An alternative is to allow for multi-homing - having accounts on more than one platform and, if possible, mirroring all content. Several solutions have been proposed for automatically re-posting anything you tweet to Mastodon. This includes pleroma-bot and mastodon-bot, though it has become much more tedious that it used to be, as it now requires you to apply for all kinds of access tokens and access levels. I'm not even sure Twitter still has enough employees to review all the requests.
For those who don't know: I have had a Mastodon account for years. I sadly neglected it in recent times, because my preferred solution for reposting my tweets to Mastodon, t2m, ceased to function a while back because of broken Python dependencies and issues with access tokens. I guess it's high time to consider the alternatives.
September 22 2022 00:29:24.
Innovation policy in times of climate change
For those who read German, my short piece on innovation policy in times of climate change went online on the German language science communication website Makronom last week. The piece forms part of a series organized by Economists For Future - a very important initiative - and features a number of other important contributions, among others two articles by my friends and colleagues Claudius Gräbner-Radkowitsch and Linus Mattauch respectively (each with coauthors).
Of course, innovation policy is a very large field that cannot be exhaustively addressed in a short article. Instead, I highlight four specific aspects of it in the article. I would argue these four aspects to be either of particular importance or particularly obvious in terms of their impact: (1) Market power and network externalities, (2) the impact of automation, (3) the - unfortunately too often neglected - innovation speed by technology as represented by cost curves, and (4) changes to the social sphere with fake news and echo chambers in online social media. Each of those is summarized only briefly, but relevant research articles linked. For more, hit the link above.
September 02 2022 20:41:20.
EAEPE 2022 conference next week: Here are the sessions on complexity economics (Research Area [Q])
The EAEPE conference 2022 in Naples is coming up next week. Research Area [Q] (Complexity Economics) will have two sessions with many interesting talks. One session ("How do complex economic systems work: Ergodicity, networks, and novelty") will be on Thursday before lunchtime, the other one ("Complex dynamics in economics: Prices, performance, and phase transitions") on Friday morning.
It appears, the local organizers are doing an outstanding job, making sure that things are not only very well-organized on site, but that it is possible to follow the talks online - using BB Collab like in the last two years.
The detailed program of our two sessions is as follows:
| 11:30-13:30 | Sept. 8 2022 | Session Complexity Economics 1 | How do complex economic systems work: Ergodicity, networks, and novelty |
| 11.30 | Mark Kirstein, Ivonne Schwartz | Max Planck Institute for Mathematics in the Sciences, Leipzig | Time is limited on the road to asymptopia -- Asking the ergodicity question while validating ABMs (Abstract) |
| 12.00 | Nils Rochowicz | Chemnitz University of Technology | Adressing Scaling in Novelty Metrics (Abstract) |
| 12.30 | Alexandre Ruiz, Arnaud Persenda | Université Côte d'Azur, Sophia Antipolis | Autocatalytic Networks and the Green Economy (Abstract) |
| Session Link | Room: 1.1 |
| 9:00-11:00 | Sept. 9 2022 | Session Complexity Economics 2 | Complex dynamics in economics: Prices, performance, and phase transitions |
| 9.00 | Karl Naumann-Woleske, Max Knicker, Michael Benzaquen, Jean-Philippe Bouchaud | École polytechnique, Palaiseau | Exploration of the Parameter Space in Macroeconomic Models (Abstract) |
| 9.30 | Anja Janischewski, Torsten Heinrich | Chemnitz University of Technology | Exploration of phase transitions in an agent-based model of margin calls and fire sales in a scenario of declining growth rates (Abstract) |
| 10.00 | Bence Mérő, András Borsos, Zsuzsanna Hosszú, Zsolt Oláh, Nikolett Vágó | Magyar Nemzeti Bank (National Bank of Hungary), Budapest | A High Resolution Agent-based Model of the Hungarian Housing Market (Abstract) |
| 10.30 | Nikolas Schiozer | University of São Paulo | Price formation and macroeconomic performance as coevolutionary phenomena in an agent-based model (Abstract) |
| Session Link | Room: 1.6 |
Of course, there will be a large number of other sessions at the conference that are also quite exciting. Besides the two keynotes by Eve Chiapello and by Laura Carvalho, I'm looking forward to the sessions of RA [D] (Technological Change and Innovation), [S] (Economic Simulation) and [X] (Networks) in particular.
March 16 2022 01:45:53.
EAEPE 2022 Research Area [Q] call for papers
Everybody is looking forward to - perhaps - having conferences in person again this year, including the EAEPE conference in Napoli in September (Sep 7 - Sep 9 2022). And so I am pleased that Research Area [Q] - Economic Complexity will have its own call again. This time, the focus is on the disruption of economic systems result from several distressing recent events. This includes the still ongoing pandemic as well as the horrifying war following the attack on Ukraine. What can we contribute to analyzing the disruption ov eceonomic systems? What can we contribute to mitigating them? What can we contribute to policy decisions and to the ethical aspects of this.
The call for abstracts is online here; the submission deatline is April 1.
September 25 2021 15:46:06.
Opinion polling for the German federal election
While I did not want to talk about the German federal elections this Sunday here, I have to comment on the state of opinion polling in this country. Earlier this year, the Green Party was predicted to come out first with >25% of the vote. Then they collapsed, even before voters got to see Analena Baerbock's forgettable performance in the election debates. The social-democrats (SPD) were polling below 15% just a few months ago, now they are predicted to win with Olaf Scholz becoming chancellor. The conservatives (CDU/CSU) were flying high, close to 40% during the early days of the pandemic, then they were down to 22%, up again, now down again. Predictions for the smaller parties are somewhat less volatile, but not much. Political commentators often give the flimsiest of explanations for these seismic shifts: Analena Baerbock reiterated other people's ideas in her book without acknowledging every one of them (she didn't actually quote them, so this is not a plagiarism case). Olaf Scholz couldn't name the price of a litre of gas in an interview. Armin Laschet, the conservative candidate, laughed when he shouldn't have. What gives?
This is actually really bad. If the polls are erratic, it probably means that they don't carry a lot of information. Poll participants may not take them serious or use them to vent their indignation over smaller issues without changing their intention to vote for the same party as always. Or the sample sizes may simply be too small.
...speaking of which: What are the sample sizes? And how do they translate to confidence intervals? In news articles (or on Wikipedia, for that matter), the sample sizes are usually not reported. Looking at the websites of the polling institutes and firms, it turns out that they usually interview between 1400 and 2100 people per poll. Some of the more dilligent ones also give some details on the methodology, especially the estimation of the bias.
Schnell and Noack (2014) had an interesting paper considering the accuracy of opinion polling in elections (specifically considering German elections) back in 2014. Polls need to keep track not only of random deviation expected in any sample of their sample size compared to the population (i.e., variance of the estimate), but also the bias in what people say and who will talk to them at all compared to the general population. This is a major problem. Experience shows that the inclination to vote for Neo-Nazis and the right wing in general tends to be underreported (yeah, people are still ashamed of doing that; maybe not a bad thing) while people overstate their likelihood to vote for parties that are seen as established, sciency and reasonable, such as the Greens. However, without details of how polling companies account for that, associated errors are difficult to quantify.
There are also biases that are introduced by the interviewer, how they act, what they say. This is known as deft and is impossible for non-insiders to account for, because we do not know who interviewed how many people and which ones.
Which leaves the regular variance. Following Schnell and Noack (2014) again, you can take a simple model with Gaussian variation of estimates (and errors) and compute 95% confidence intervals for estimate p and sample size n as (p +/- 1.96*deft*sqrt(p*(1-p)/n)) where 1.96 is the z-score of the Gaussian at 2.5% and 97.5% (so 95% confidence). For estimates around 24%, which are currently reported for the two larger parties, the conservatives and the social democrats, that will be 24% +/- 1.9%, so 22.1% to 25.9%.
While the polls see the social democrats in the lead, the two are clearly within each other's confidence (although you may argue that with multiple polls with similar results the confidence should increase) and should be seen as too close to call. For the smaller parties with lower predicted percentage points, the confidence intervals are a bit narrower.
And yet, given what we know about the volatility of the polls in recent weeks, I have difficulty believing this. I am guessing that a lot of the answers given in those polls do not actually reflect people's intention to vote and I would not be surprised if we find out that the polls were 5% or more off compared to the actual results. The SPD and the CDU/CSU are still going to win, and chances are that they will continue both their coalition and their policies (why change anything if everything is going so well?), but maybe news media and polling firms will learn some humility and may start reporting errors or confidence intervalls for the next election.
September 19 2021 03:25:05.
Investigating structural change at the microlevel
Our article on structural change at the microlevel in China was published in the Journal of Evolutionary Economics this week; it was also featured on the OMS website. Situated at the intersection of understanding structural change and analyzing what might be behind China's rapid rise into the ranks of developed economies, this was quite and interesting research project. I'll take this opportunity to add a few notes on how this paper came about, what we found, and where to go from here.
Structural change is often and mistakenly understood as a rather directed and homogeneous process. Economies shift from agriculture to industry to services, right? While this is not wrong as a first approximation, there is a lot of variability in the details. What is more, the reallocation of employment (or capital, or particular kinds of labor and capital) may behave wildly different from changes in output. There are, of course, some statistical consistencies, known as Fabricant's laws after Solomon Fabricant's 1942 empirical investigation of the US economy and its development.
We were lucky enough to have access to data on China both at the firm level and at the sectoral level to check some of Fabricant's and later scholars' (e.g. Stan Metcalfe's) findings in the context of rapid economic development. It was Ulrich Witt who suggested attempting to confirm Metcalfe's findings using firm level data. We couldn't. At the sectoral level the correlation laws check out, at the firm level they don't.
Now, how can that be? Is the internal organization of sectors just random with little consistency between different structural variables like employment, value added, growth of either of these, productivity, etc.? Is any consistency that exists already captured by the sector? Are there other non-trivial structures (say, supply chains, ownership)?
In any case, sectoral growth is still a prefictor for firm level growth, no matter which structural variable is used to growth is measure that growth. Regressions confirm that. However, the relationship is not linear. Also, robust regressions have to be used, because the error terms turn out to be heavy tailed and OLS becomes therefore unreliable. The presence of heavy tails lurking somewhere in our data is not a big surprise by the way - not to us anyway. And it has intriguing consequences in itself, something we analyze in more detail in this paper.
What practical lessons can we draw from this? First, since almost all the empirical laws come apart completely at the firm level, it is fair to conclude that sectors are not simple groups of firms that happen to produce similar things. Were that the case, the micro-level picture should, on average, mirror the aggregated one. Instead, the correlation laws seem to emerge in the sectors and as properties of those. In practice, this might reflect ressources that are shared by the firms in the same sector and region: the infrastructure, the innovation system, the institutions, the labor force including their intangible capital. So this is what development policy should aim at, not the individual firm, no matter how impressive it's economic performance might be.
Second, and most intriguingly: Can China's economic success be repeated elsewhere, in all or any of the many developing economies? Unfortunately, this is hard to say without good empirical data on these countries - and at the micro-level, if possible. And that is indeed one of the promising options of future research. If anyone has the opportunity to analyze micro-level data for Angola or Bangladesh or Vietnam or Zimbabwe, use it. Failing that, it should also be quite interesting to investigate the changes innovation systems undergo during rapid economic development (presumably from playing catch-up to taking a leading role), the role of the infrastructure and economic policy (this is already well-researched, but not necessarily in its impact on the firm level), etc.
March 24 2021 05:07:04.
EAEPE 2021 Research Area [Q] call for papers
In spite of significant progress with vaccinations, tests, treatments, and understanding Covid-19, the pandemic is far from being defeated. As a result, academic conferences will continue to be held online. Yes, there is often little interaction besides listening to talks that might as well be recorded in advance. Yes, in terms of traditional in-person-meetings, this is not ideal, though perhaps the best we can do under the circumstances.
But there are other possibilities that we can leverage, possibilities that we do not have in traditional in-person-conferences. Geographical distance is meaningless. We can look up papers and fact-check unusual claims without having to meddle with the wifi in an unfamiliar institution. We have all the amenities of our own homes. We can easily record talks. We can leverage social media. It may be helpful to have a permanent Jitsi hangout room besides the session rooms; it may be worth setting up a Nextcloud for sharing material, it may be worth having persistent chats. Since this is the second year now, we already have expertise. We shall do our best.
Of course, Research Area [Q] - Economic Complexity will be part of these efforts. Our call for abstracts is online. We will again put a particular focus on the economic fallout of the Covid-19 pandemic and on ways out of it. However, we also welcome other contributions that have a connection to complexity economics.
March 18 2021 00:46:03.
What an ABM on systemic risk in insurance will tell you
A few years back, we started developing an agent-based model (ABM) of the insurance market to investigate - among other things - systemic risk. The paper on the model and our findings was published last week. A working paper version had been out since 2019.
The paper has generated quite a bit of publicity.
- Christopher Cundy from InsuranceERM reported about the paper. He also spoke to us earlier this week and also interviewed representatives of the UK and EU insurance regulators (PRA and Eiopa) as well as of the open source Oasis Loss Modelling framework.
- Steven Evans from Artemis.bm reported.
- Luke Gallin from Reinsurance News also published an article about our study.
- The case studies website of the Mathematical Institute at the University of Oxford is publishing a summary.
- See also the INET Oxford press release.
What did we find? It turns out that catastrophe insurance is subject to a variety of heavy-tailed distributions (how often do hurricanes occur? what is the expected damage an earthquake will cause?) that will also change over time. Insurance companies use third-party risk-models to assess the risks they are taking; this is subject to regulations like Solvency II and needs to be approved by regulators. Necessarily, all of these risk-models are inaccurate. The question is now - in what way are they inaccurate? Are different firms using different models? And what happens if not? Is risk-model homogeneity important? If everyone uses the same model, everyone will be in trouble at the same time. With additional risk contagion channels from reinsurance and through the finance system, this bears the potential of a bankruptcy cascade.
So what should we do? Should regulators just relax requirements for risk models and allow whatever? No, of course not. What they should do is encourage diversity in the industry. From a macro-economic point of view, bankruptcies of individual insurers are problematic, but manageable. What we really do not want is a bankruptcy cascade. Governments have a number of fiscal and regulatory tools at their disposal to promote diversity of risk models, ranging from tax benefits for taking into account additional risk models to subsidies for risk modelers to open access risk models (such as Oasis Loss Modelling) to many regulatory mechanisms. According to InsuranceERM's reporting (linked above) about our study, both risk modelers and regulatory bodies are aware of this and important steps have been taken in this direction in recent years.
What are the next steps with respect to our ABM? Obviously, the insurance system has many complicated aspects that could also be investigated with our ABM. Back in 2019, we were working with summer interns who implemented some additional features and started building some very impressive tools to calibrate the model (using the method of Morris...). This was after the initial working paper version, so these results are not yet in the paper. Since the funding for the project dried up, we had to focus on other responsibilities since, but we do hope to get back to the insurance ABM to continue our investigations.
The code of the ABM is open source, however. It is available on github, as is the extended version resulting from the internship project in 2019. Currently, the code requires the sandtman library by Sandtable, which is not currently free software, but takes care of the parallelization of different runs of the model. (Sandtable graciously allowed us to use their infrastructure for our simulations.) At the request of other researchers, we will make a version that does not rely on the sandman library available, although this makes the simulation rather slow.
January 08 2021 02:53:01.
Angry conspiracy people stormed the US Congress - what can we learn from this?
In light of the events on Wednesday I have to comment on US politics yet again. I have done this too much already over the past few months. However, there are some important things to point out.
What happened? Donald Trump's far-right thugs stormed the Congress; they had complete control over significant parts of the building for several hours. Some of them looted the offices, some wandered around aimlessly, some uploaded pictures of documents and computer screens with potentially confidential information on the internet. DC police and Congress police were only there with a handfull of officers and could not hope to stop them. The unpreparedness of the police is the most surprising part of the incident.
Since Wednesday, politicians, celebrities, and reporters are calling for the perpetrators to be brought to justice and for the president, who instigated the attack, to be removed from office. People have far too much faith in the justice system. Laws are no good if the police is incapable or unwilling to enforce them. This is not so much about the officers around the US Capitol, more about those who deployed the forces on such a day in a way that made it impossible to stop this completely predictable attack. It does not matter if this is gross incompetence or a deliberate signal to congress (i.e., "don't defund the police"), it is clear that DC police is not to be trusted.
On a related note, some agents in Joe Biden's Secret Service security detail had to be exchanged because they were Trump loyalists and there were concerns whether they would be willing to effectively protect the president elect. The most important task for the incoming administration is clearly to get the government agencies under control again. We have experimented with govermnents whose institutions were not willing to protect them before. They did not last long.
After the incident, leaders of congress stepped in front of the cameras and claimed victory; "violence never wins". You get the impression that this is a desperate lie they tell Trump's supporters to keep them from rioting. No, it's not that easy. Violence is not self-defeating. Defending democracy actually takes work. Far-right thugs will not suddenly recognize the error of their ways. The Republican party will not suddenly come to their senses after Trump is gone. In fact, yesterday's Yougov poll shows that 45% of Republicans support the storming of congress, and therefore, presumably, a violent overthrow of the constitution and an end of democracy. And this is not just a poll. It's not just an indication for the possible outcome of the next election. These are the people in the institutions, in the security forces, in the local chambers of commerce; these are the people who run the country - about a quarter of it anyway.
The only good thing about this incident is that we can learn from it. When you break a system you learn where its weak points are. Here's a picture of an unlocked computer with email and various other programs open; apparently this is in Nancy Pelosi's office. Apart from the fact that the person who posted it - Elijah Schaffer - admitted to multiple crimes by doing so, it has some important implications for Congress' IT security. Not only will DC police allow far-right thugs to stroll into the Capitol, look at everything and modify hard- and software at will, Congress is unable to provide a system that ensures computer security when physical security of the equipment fails. Ideally, you would want strong encryption, an operating system that is not Windows, and, crucially, screen lock with sufficiently secure authentication required to log in. For crucial institutions and infrastructure, it is possible to lock all computers in the building centrally. None of these requirements are out of these world. Yet, if we are unable to implement these in the office of the Speaker of the US House of Representatives, what kind of computer security should we expect in a private firm or in the office of a low-level government official. Efforts of big tech to centralize authentication to everything else in their systems are not helpful and should be outlawed. Now, you only need to fins a far-right Facebook employee and he'll unlock every computer in this world for the Proud Boys. Nice.
It is clear that we have a lot of work to do. For everyone, that includes thinking hard about computer security, about how to keep the economy safe, how to secure public safety, even if democracy comes under attack, even if public order breaks down. For the US, it includes saving democracy itself.
November 10 2020 05:15:20.
The predictions for the US election were wrong again
So Joe Biden and Kamala Harris have actually won. I confess, I was surprised, given how the early results on Tuesday evening turned out. It remains to be seen if Trump and his team will actually go quietly (or at all for that matter). I believe, I have said that before.
What really surprised me, however, was that all the polling firms and all the analysts and all the predictions were wrong. Again.
Here is how much. The figure shows the predicted and actual percentage differences between Trump and Biden. I know that this double-counts the votes shifting from one candidate to the other, but since there may be third party candidates, this still seems to be the bes way.
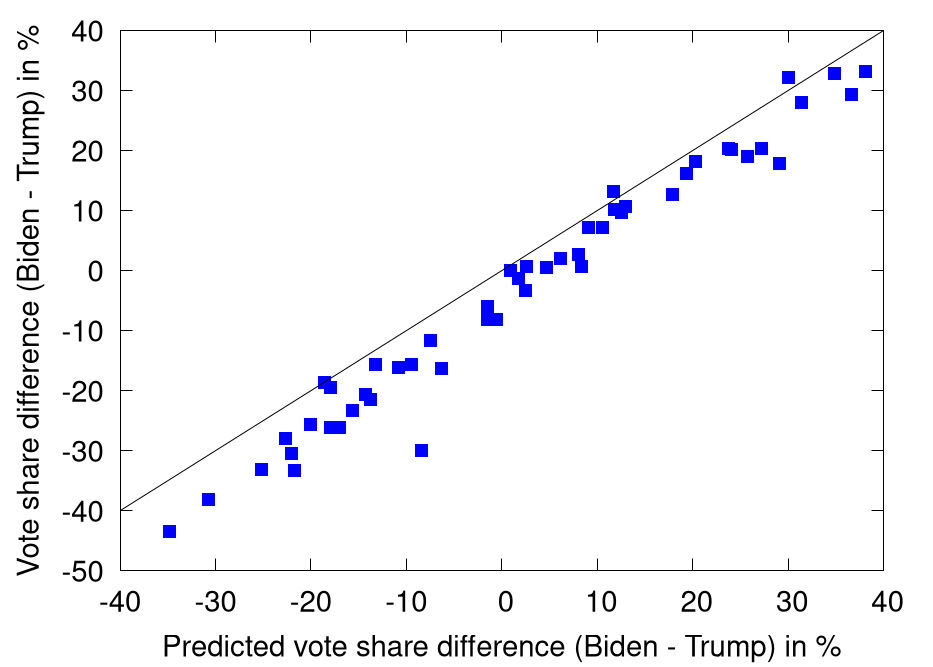
If the predition was reasonably exact or at least unbiased, we should expect to see the data around the 45° line. Clearly that's not the case. In fact, the bias seems even more systematic than in the election four years ago. Back then, the polls tended to underestimate Trump in red states and Clinton in blue states. This year, they underestimated Trump basically everywhere.
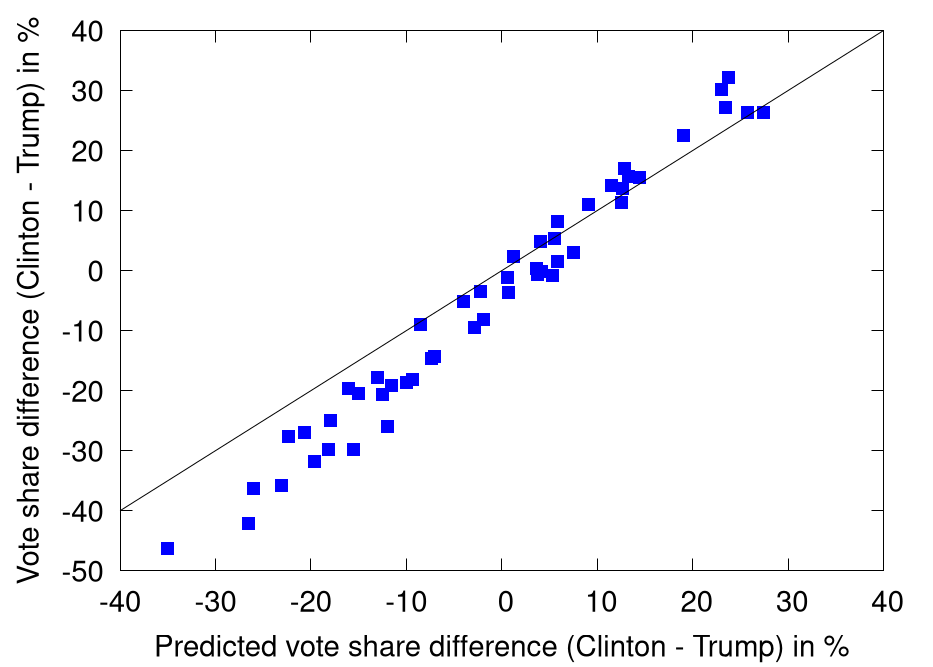
Now, people keep saying the polls were not that wrong. For almost every state, the final result was still in the standard deviation of the prediction, though not necessarily by much. That is true, but I was under the impression that the errors are supposed to come mostly from prediction errors for these states and not from systematic biases, i.e. that the deviation of the states from the predition should not be highly correlated. Alas, with this hope, I was disappointed.
What is more, the bias four years ago is even a strong predictor for the bias today, R²=0.25.
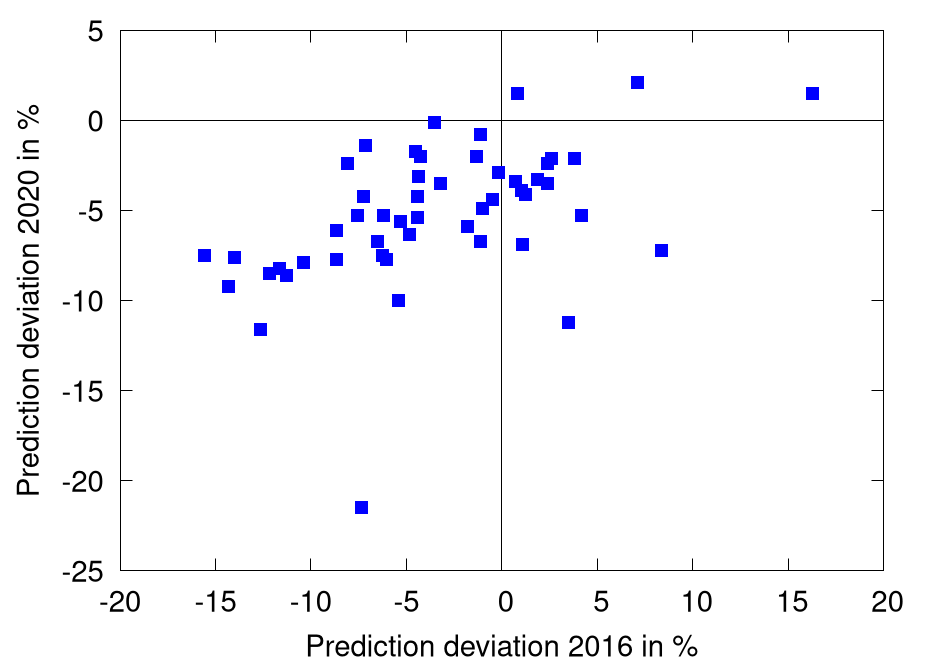
Disclaimer: This was done really, realy quick and dirty. The votes for 2020 do not repesent the final results (which are not in yet). And there may be some statistical artifacts that I missed. The data in CSV format is here
Nevertheless, I'm confident that the preditions and analyses were off by an awful lot. It is, in fact, a big deal since these predictions are used by some people to make the decision to go vote or not. Since it is not the first time either that this is systematically off, I think the question why this keeps happening deserves an answer now.
October 18 2020 21:05:54.
Is democracy protecting civil rights and liberties?
There was an election. The dominating issue was race. Some parties played to voters' fear of black people, their fear of losing their jobs because of minority groups offering cheap labor, their fear of street violence and crime, their fear of the political left and of communism. They proposed to disenfranchise large parts of the population - more so than was already the case. The septuagenarian leader of the party driving this push was a populist, notorious for lies and smear campaigns. The opponents, well-respected statesmen, were unable to counter his campaign effectively. Sounds familiar? No, I'm not describing the upcoming US election. I am describing how the Apartheid regime started in South Africa.
It was late May 1948 and winter was approaching in the Southern hemisphere when South Africa held that fateful national election. On May 26 1948, the Herenigde Nasionale Party, formerly a right wing fringe group, was victorious and its septuagenarian leader Daniel François Malan formed a coalition government with the Afrikaner Party. Together, they had only 42% of the vote, but 52% of the seats (yeah, gerrymandering was already a thing back then). Black people made up 70% of the population but had already been removed from the general voters roll in 1937 and could only elect four representatives - whites, of course - out of 160 members of parliament.
This was about to change, however. Malan and his coalition had drawn up the blueprints for Apartheid before the election and moved quickly to put them into practice. What followed were the Prohibition of Mixed Marriages Act (1949), the Immorality Amendment Act (outlawing interracial extramarital sex, 1950), the Group Areas Act (segregating residential areas, 1950), the Suppression of Communism Act (branding opposition to Apartheid "communism" and making it illegal, 1950), the Population Registration Act (introducing official racial classification of the population on ID cards, 1950), and many, many more Apartheid laws. They gradually disenfranchised all non-white voters completely, packed the supreme court with additional ultra-racist judges in 1955 after the court had struck down some of the early Apartheid legislation, and proceeded to forcibly remove non-whites from large parts of the country. Malan won another election in 1953, again without plurality of votes, was succeeded by Strijdom in 1954 and by Verwoerd in 1958. By then the opposition had been practically suppressed.
While this process was clearly not legal, it did mostly follow democratic process, albeit the rules were bent considerably. There was no uprising of proponents of civil liberties in the population, there was no outcry in the international community against the injustices that were about to happen for quite some time. Everything proceeded gradually, one small step at a time. Democracy for white people was never completely dismantled (although opposition to Apartheid was, of course, illegal).
This is how civil liberties can be dismantled and civil rights removed for large parts of the population, all the while following the constitution and the democratic process. All you need is a bunch of committed followers, that are willing to bend the rules, that are louder and more well-organized than those defending civil rights, and that are preferrably also armed.
If you do not think this could happen again in the US this November, think again. If you do not think this could happen in Europe, think again. The governments of Poland an Hungary are actively working to remove civil rights and civil liberties. They are dismantling checks and balances in their countries. They are also fairly open about it and about the fact that they will mutually prevent EU sancrions against one another (those would require unanymity except for the sanctioned country). Other countries are at risk, too, France (with elections in 2022 and Le Pen head to head with Macron in the polls) and Italy in particular. The UK has already allowed itself to be pushed around by Nigel Farage, Steve Bannon, and various other far-right people for qiote some time. Germany seems pretty stable, but once Merkel steps down, all bets are off.
What is perhaps the most frightening prospect is that the various autocrats that have sprung up around the world, Bolsonaro, Putin, Modi, Duterte, Erdoğan, may, at some point figure out that they can now stop with the charade of pretending to continue to hold democratic elections now and then. Once there are no economically or politically powerful governments any more that defend democracy, what's the point?
October 01 2020 23:30:42.
Change of scenery, not of research interests
Just a brief note: I have accepted an appointment at the Chemnitz University of Technology, where I will hold the chair for Microeconomics (VWL II) starting today. This comes with new responsibilities, of course, and I will spend quite a bit of time teaching (online courses this term because of Covid-19). However, I will continue working on the research topics I have come to know and love in Oxford (and in Bremen before that) and with my friends and colleagues in Oxford and elsewhere.
September 20 2020 21:36:27.
Guttenberg has written a second PhD thesis
Remember Karl-Theodor von und zu Guttenberg, former German minister, husband of Bismarck's great-great-granddaughter, and darling of the German tabloid press? Yeah, he has written another PhD thesis. His first one, in jurisprudence, did not work out that well. When it was discovered in 2011 that he had copied extensively from another text, his title was revoked and he had to step down as minister of defence.
Now he has tried again; this time in economics and in English. He received a PhD from the University of Southampton, where he submitted a thesis on correspondent banking in November 2018, supervised by Richard Werner. The thesis was submitted under the name Karl Buhl-Freiherr von und zu Guttenberg, omitting the "Theodor" part of his first name that he used to include and also changing his last name compared to the form given on his first thesis - I suppose this is one of the advantages of being a member of the nobility: The number of permutations of your first and last names you can use for short forms, if you don't want to be recognized immediately, is huge. In any case, if he had hoped to keep his doctoral studies free of drama the second time, he was disappointed: His advisor left the University of Southampton before Guttenberg had submitted. He is now sueing his former university for GBP 3.5m as he feels he was discriminated against because he is German and because he is Christian. Another faculty member took over Guttenberg's supervision.
{kind=link}
Back to the thesis. It is quite brave to take another stab at gaining a PhD after the drama with which he lost his first title. It is even braver to venture in a completely new field, economics, no less. The thesis topic is not exactly my field of expertise, but it does sound interesting, even if it hadn't been written by a celebrity, so let's take a look.
The specific title reads "Agents, bills, and correspondents through the ages". The subtitle is three lines long, but it does make it evident that the thesis is actually in economic history. It also follows the form you would expect for a thesis in history: It is nearly 500 pages long, uses the notes and bibliography citation style common in history instead of the author-date style typically used in economics, and many sentences are very long and complicated. It also does not give the reader a lot of guidance; there are no chapter introductions and you have to guess what he is doing next and why.
Form aside, it seems like a serious, detailed, and surprisingly interesting historical analysis. Chapter 6 is a case study on how English troops fighting Louis XIV in the Spanish Netherlands (i.e. Belgium) during the Nine-Years-War 1688-97 were paid through local correspondent bankers of the nascent Bank of England. This must have included substantial and tedious work in archives. That's right - England was in need of funds, because the Enlish navy had suffered a crushing defeat and the Bank of England was founded in 1694 to help England win the war. The financial operations conducted to make that happen were, of course, meticulously documented.
The relevance of all this for the present day is, as with many works in economic history, rather limited. It is common to make sweeping generalizations based on some specificities in economic history. Events appear to follow a logical sequence in hindsight (hindsight bias) and the frequency and significance of historical aspects on which we have data is overestimated (an aspect of availability bias). Of course, it would be unfair to blame Guttenberg for that, since these are structural problems of the field of history (with the possible exception of computational historians like Peter Turchin), of which many historians sadly appear mostly oblivious. Nonetheless, Guttenberg's thesis also suffers from these problems. For instance, he appears to backdate the idea if not the concept of correspondent banking to Babylonian antiquity. He shows that there were isolated cases of similar proceedings scattered over centuries, neglecting that we know almost nothing about ancient Mesopotamians financial transactions for almost all time periods. Similarly, Guttenberg tries to leave the impression that correspondent banking will remain asignificant part of the banking system in the short term, although he correctly lists both problematic aspects (financial contagion risk) and alternative technologies (online money transfer systems like TransferWise, blockchain and other distributed ledger technologies, etc.) that should expediate the decline of correspondent banking. Unforeseen events like the Covid-19 crisis may or may not speed up this process and change many aspects of the economy, including the international payment system, significantly.
September 20 2020 16:21:16.
Is it unlikely that Donald Trump will be reelected in November?
2020 has been a terrible year so far with a devastating Coronavirus pandemic, the continued slide of the world into authoritarianism (remember the elections and referendums in Poland, Russia, Belarus?), devastating forest fires, and the stunning development of all kinds of conspiracy theories into mass movements. It is not over yet. The event the world is waiting for are, of course, the US elections in November. They are important, not only because the US has considerable influence around the globe, but also as a signal with regard to the future of international cooperation (remember how the US left the WHO in the middle of the pandemic?), the fight against Covid-19, and the future of conspiracist movements. And of course, among national leaders the US president is matched only by Jair Bolsonaro in his mishandling of his government's response to the pandemic - not that there wasn't enough competition.
Donald Trump has lost some support in mishandling the pandemic, with his sometimes chauvinist and sometimes non-sensical comments, and in supporting fringe positions on all kinds of issues. Everyone seems to be sure that Donald Trump is going to lose re-election. However, that alone will not necessarily make it so. In 2016, everyone was sure too that he was going to lose. The Democratic Party's campaign - both then and now - has been unimaginative to put it mildly. And while he desperately tries to appear like - and perhaps is - a quirky, unhinged narcissist, his campaign people seem to know what they are doing.
His poll numbers are up; since July he steadily seems to be narrowing the gap to his opponent, Joe Biden. Biden's remaining lead is slightly over 5 percent. It is also worth remembering that Trump does not need to win the popular vote, he only needs to carry enough states with sufficiently many votes in the electoral college. This has in recent times always worked in favor of Republican candidates. And quite a number of swing states are now within reach, not least Florida, which has 29 votes and which he might woe by nominating Barbara Lagoa for Ruth Bader Ginsberg's seat on the Supreme Court. She is certainly conservative enough for him and he seems exactly like the kind of person who would use a SCOTUS nomination in an electoral campaign.
Of course, he might still lose. It might all not be enough. He might show a dismal performance in the upcoming debates. But he also has an abundance of administrative tools that he can leverage - from strategically announcing another lockdown to allowing government agencies to harrass voters to making vote-by-mail difficult.
In any case he will leave a distinct legacy, a government in disorder, a supreme court packed with ultra-conservative judges, and a ubiquity of conspiracist militias devoted to him. I don't think it is enough for them to seize power; I don't think he intends to seize power if he loses the election. But it is definitely enough to make the live of the next governments hard, be that the one led by Joe Biden, that led by another Democratic or Republican candidate in 2025 if Trump continues for four more years, or that of the first women of color to become US president if Biden wins but has to step down for age-related or other causes during his tenure.
September 02 2020 15:08:55.
For the first time, the EAEPE is holding an online conference
Indeed, the EAEPE is holding an online conference this year. The keynote by Genevieve LeBaron on "Combatting Modern Slavery" has just started and everything seems to be working quite well. I am very happy about that. I have to admit that I had doubts. The keynote as well as other sessions will be recorded and be made available online.
This year's conference organizer Jesus Fereiro joked that they always intended to make this year's conference different and memorable. That has certainly been achieved, albeit not in the way they anticipated. I hope that it will indeed remain the only conference that has to be held exclusively online, but I am not convinced this will not se a repeat next year and after if the pandemic is not under control by then. On a different note, it is also a chance to build experience in long term online cooperation on research projects. So far, the available tools still seem oddly ad-hoc and in case of Zoom et al. a major privacy risk. But maybe better solutions are about to emerge.
Given the continuing pandemic and how it is not under control, I suspect, we will have to organize quite a substantial part of scientific exchange online over the next few years. Covid-19 continues to rage even in developed economies that make every effort to control the pandemic. Developing economies that cannot afford to take such measures are much worse off, and so are economies, where the administration refuses to deal with the situation.
There are justified concerns that the pandemic will seriously harm scientific exchange. Attending talks may be possible, but the informal meet and greet will be more difficult. To be honest, I have difficulty imagining technological solutions for this. The EAEPE is trying its best to make this work in Online Town meetings, while for the main conference Blackboard Collaborate is used, an expensive commercial, but more privacy-conscious solution. I am looking forward to an interesting, unique, and technologically sophisticated conference and to the Online Town meetings in particular.
April 29 2020 16:50:19.
EAEPE 2020 online conference
In the beginning of April already, the EAEPE has decided that this year's conference will be an online meeting. Given the continuing epidemic, this was no doubt the right decision.
Of course, our Research Area [Q] - Economic Complexity will be part of that. The original deadline last month has been extended and is now upcoming tomorrow. Research Area [Q] will be placing a focus on economic aspects of the epidemic this year, a topic that is both highly relevant and in spite of many interesting recent contributions not yet well-understood. I am very excited about this and am confident that we will have many insightful contributions. For details, see Research Area [Q]'s call for papers.
A crucial aspect will be what technology will be used for the online conference. This is all the more relevant today as the world is scrambling to transfer economic life and scientific exchange online. The technologies that will emerge as dominant will play a defining role in our lives, both private and professional for years if not decades to come. As many of you know, some technologies like Jitsi and BigBlueButton are clearly preferable for their privacy and security characteristics compared to the likes of Zoom or MS Teams. Of course, there are also performance issues. Since this is and will remain an important one for the foreseeable future (at least until the pandemic is under control, likely longer), I may write a more detailed blog post on this in the next few days. It is my understanding that the EAEPE is looking into this and is working to find a solution.
April 08 2020 03:38:48.
Finity finite moment testing package published on CRAN
Our package, announced earlier is now published on CRAN and can thus be downloaded directly from R with
install.packages("finity")
or
pacman::p_load(finity)
The manual can be found here testing version of Rtools
The package compiles and works well on Linux with recent gcc packages (9.3 on recent Linuxes compared to 4.9.3 in Rtools 3.5 on Windows) and also with the testing version of Rtools (4.0) on Windows. Rtools 4.0 should be released later this month according to r-project.org. I am less sure about Mac and about more exotic operating systems.
In any case, for old compiler versions that have trouble with the C++ 2011 standard (including Rtools 3.5 and some versions of Mac Xcode), compilation will fail with
error:non-aggregate type 'arma::vec' (aka 'Col') cannot be initialized with an initializer list
I hope that such setups will be updated quickly with the new versions of Rtools and other software. In the meantime, here is an alternative version of the package that should compile cleanly with older software including Rtools 3.5.
March 10 2020 06:14:24.
COVID-19 outbreak in Europe
Slowly, Europe is realizing how big COVID-19 actually is. If we are to get this pandemic under control, it seems quite unavoidable to place vast stretches of Europe under a complete lock-down. This will have dire consequences for the economy and for the quality of life. But it is nothing compared to what we would face if we are just a little bit too late with the lock-down.
The development of the number of cases develops roughly exponentially until it gets close to the capacity boundary (no one left to infect). Of course, in reality, it is a bit more complex, it depends on the structure of the social interaction network, and different people will on average shake different numbers of hands. Or hopefully, they have learned to avoid shaking hands by now. The average growth rate depends on this. Far from the capacity limit, it appears to be between 20% and 35% daily (numbers of infected people doubling every 2-4 days). Both isolating infected persons and placing regions under complete lock-down are strategies aimed at reducing the capacity boundary and pushing the growth of the epidemic away (down) from this maximum growth rate. This is what the WHO rightly continues to recommend every day now.
Detailed data is made available on github by CSSE at John Hopkins University. I've written a small python script to visualize this, also available on github. It is fairly clear that the European countries are still in the exponential growth regime. China seems to have the epidemic well under control, for South Korea and Japan, the rate of infection is slowing. I am afraid to think about what may happen if the bulk of the epidemic hits some less rich countries with less developed health care systems.
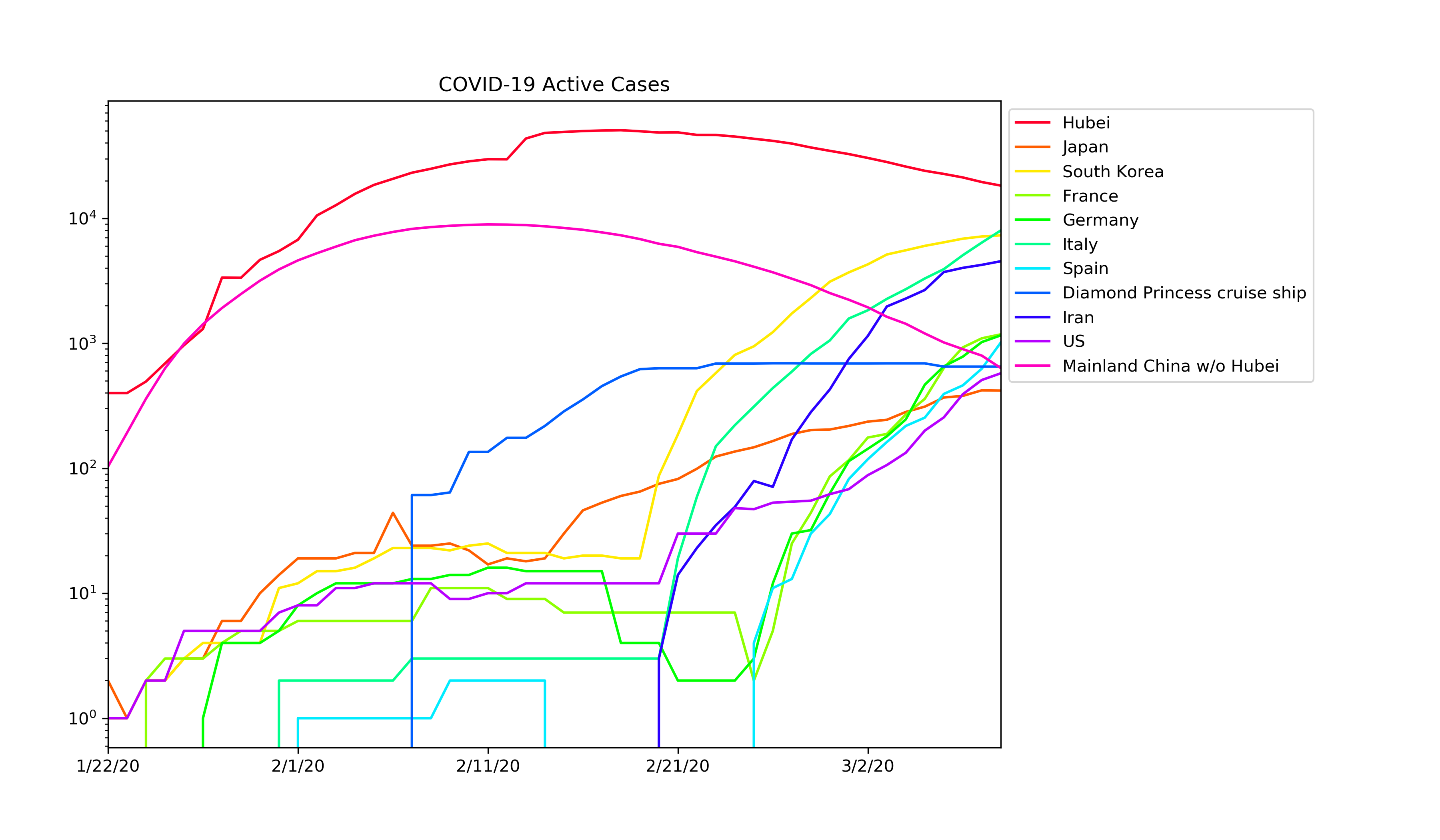
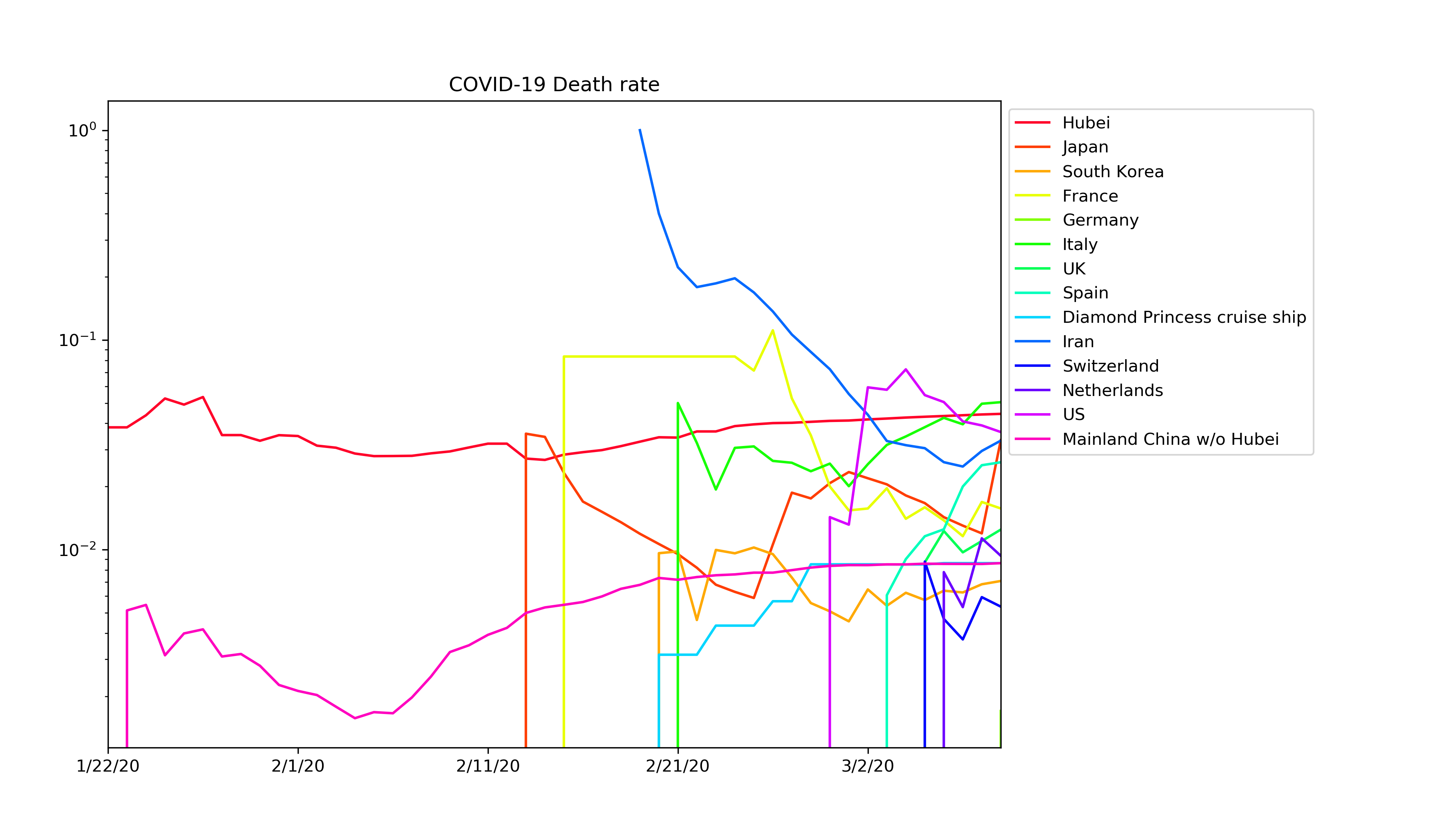
And no, death rates do not seem to converge. Instead they remain spread out over an order of magnitude or so. Presumably this depends on how good the health care system of the respective region is and how hard the region is hit. Note the difference between Hubei and the rest of mainland China; presumably the main difference is the quantity of cases compared to hospital beds.
March 06 2020 05:08:40.
R package for finite moment testing
Imagine we are interested in the dispersion of a measure; say, labor productivity. Tracking growing labor productivity dispersion may be important as it might, under the assumption of rational expectations, indicate growing misallocation of money and ressources. What dispersion measure would we use? The standard deviation seems an obvious choice. If we do this, however, we will observe that the standard deviation increases in the sample size. Dang.
This is so, because labor productivity, like many other economic variables, is heavy-tailed and has a tail exponent smaller than 2. For such distributions, the variance is infinity and any sample variance will, while finite, diverge in the sample size. We discussed this in a recent working paper with Jangho Yang, Julian Winkler, Francois Lafond, Pantelis Koutroumpis, and Doyne Farmer.
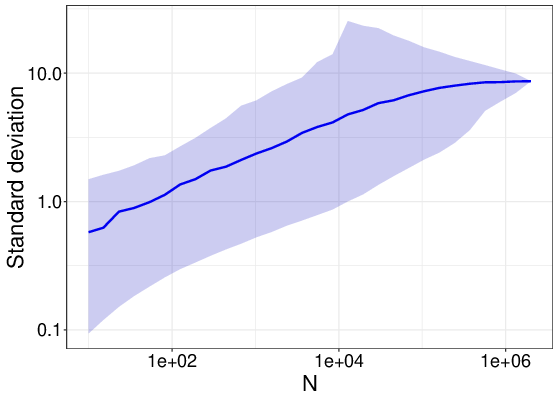
Wouldn't it be nice to have a simple statistical test for this?
In our paper, we use a finite moment test first suggested by Lorenzo Trapani. The test uses a randomized testing proceture (surrogate randomness) to a rescaled absolute moment of the sample and checking the distribution in a way that distinguishes finite from infinite moments as they appear as two different rescaled distributions with different properties. Yeah, that's a bit cryptic. Further statistical details can be seen in Trapani's paper, linked above.
More to the point, Julian Winkler and I have built an R package for Trapani's finite moment test. The code can be found on github, instructions on installation etc can be found here or in the draft manual. At some point we plan to make it available on CRAN.
October 20 2019 04:57:37.
The big step into the new millenium: Nobel memorial prize in economics 2019
Last week, the Nobel memorial laureates 2019 were selected. And it was a big departure from traditional practice. The decision single-handedly doubled the number of female economists who were given this honor (to now two), while also increasing the number of non-European/North-American laureates and acknowledging important research in development economics. Coincidentally, for the first time, the prize was given to a married couple - partly because this is generally not very likely and partly because gay marriages are rather recent and almost all laureates so far have been male. In any case it is, in a way, also a celebration of love among researchers. I love it.
However, the most radical departure from traditional practice is that the research acknowledged with the prize was conducted in this millenium. Not in the 1970s, not in the 1980s, indeed, in the 2000s. The earliest papers by the laureates cited in the scientific background document are from 2003 and 2004. It's radical. The most recent research acknowledged with a Nobel memorial prize in economics so far was Elinor Ostroms work on the commons, starting in 1990. (And even that is only true if you don't count her 1965 PhD thesis, that foreshadowed it.) In fact, a look at the data shows that we spent several decades mostly acknowledging research from the 1970s. Sure, the 1970s were fun - and especially our neoclassical colleagues will agree with that - but were they really so important?
Looking at the earliest works referenced by the Nobel prize committee (excluding often not widely circulated PhD theses) for each of the prizes the following distribution emerges.
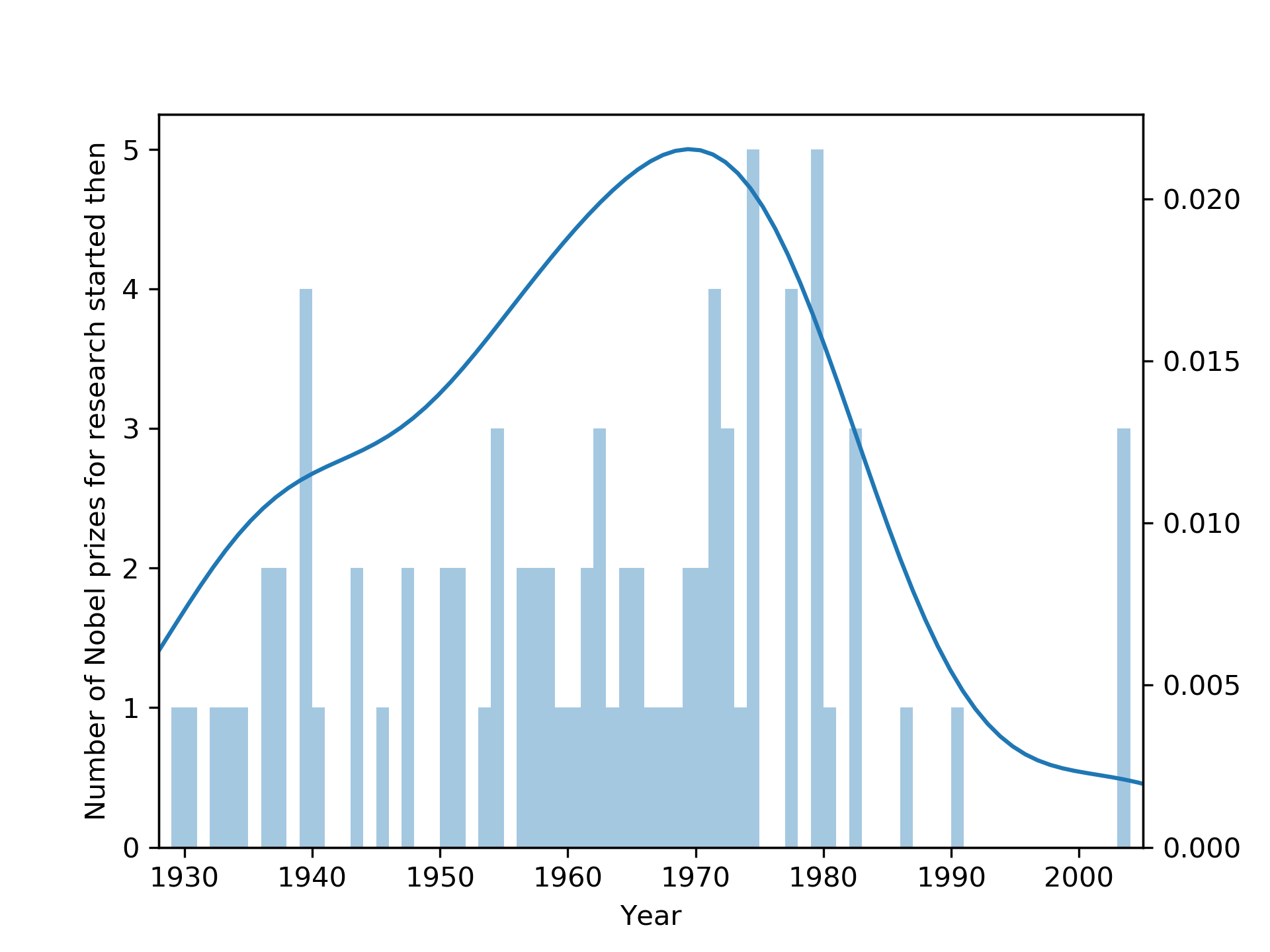
The usual tests for structural breaks, etc. (Chow, various unit root tests) fail to identify any structural breaks, likely because the data is too noisy. However, it from looking at the plot below, it is clear that comparatively recent research was acknowledged much more frequently in earlier times (consider Arrow's prize in 1972, consider Engle's in 2002). Except for the aforementioned two rare occasions, Ostrom's prize in 2009 and this year's, the age of the acknowledged research has been steadily increasing at the same pace as the the time distance to the 1970s grew. It is high time we look to new research.
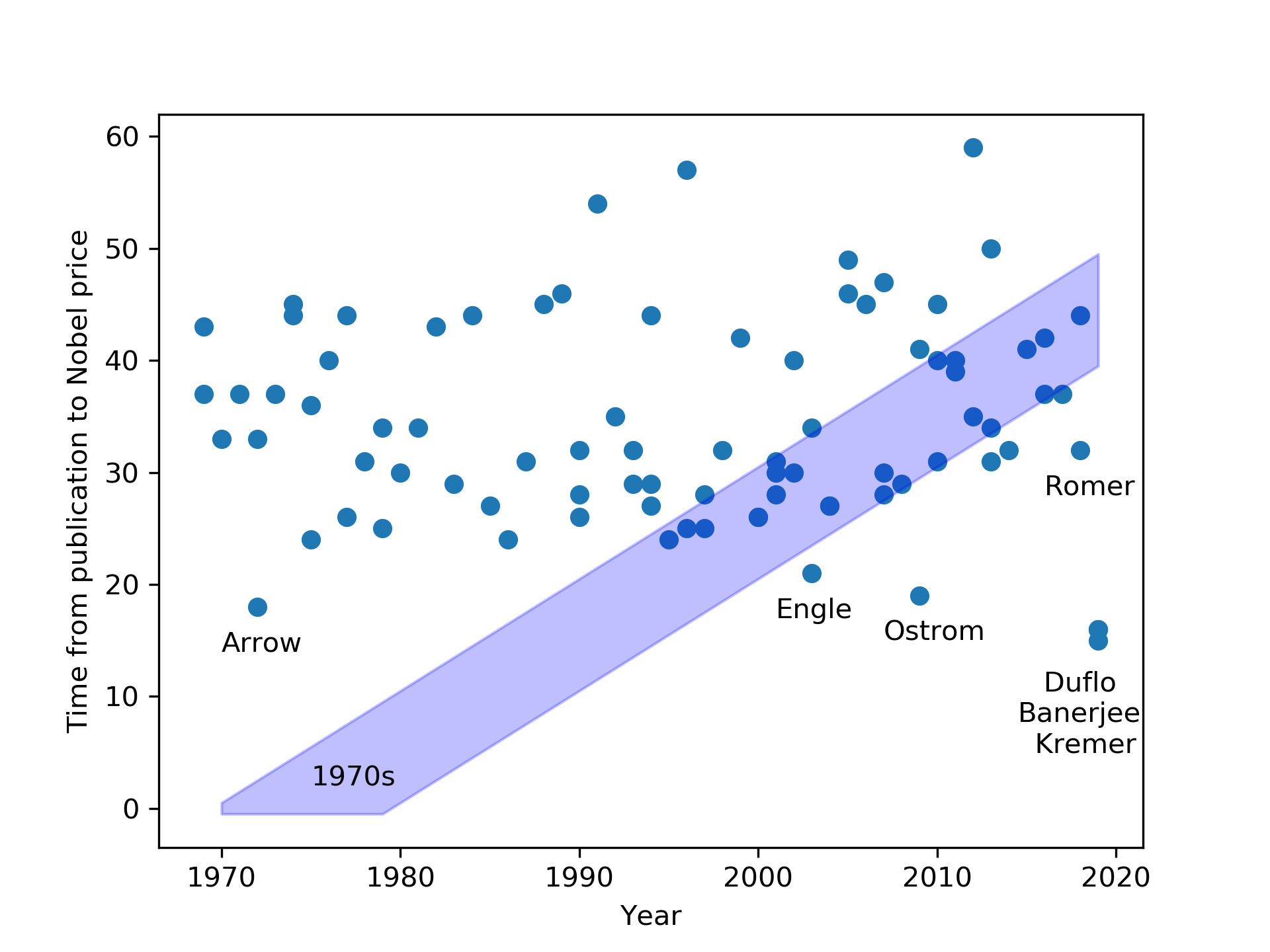
The data I used is here as feather, pickle, csv.
September 13 2019 12:31:25.
EAEPE 2019: A lot of ABM
The EAEPE conference 2019 is already under way. We had an interesting Research Area Q (Complexity Economics) session yesterday and I presented our work on dispersion in firm-level data this morning.
What I am most excited about is, of course, our special session on "Machine learning, AI, and Robotization: Effects on socio-economic systems and opportunities for economic analysis". We will have a keynote by Amir Sani this afternoon on the simulation of asymetries and artificial intelligence. Giovanni Dosi will give the second keynote in the special session tomorrow, talking about technological change and effects on the social fabric in the age of machine learning. And of course, we have an amazing line-up of contributed talks as well. Details in the program.
Naturally, the EAEPE is broader than just our special session, with many sessions on topics ranging from finance to structural change to computational economics to economic philosophy. However, I am excited to see that there are quite a number of additional sessions on complexity economics and on agent-based modelling in particular. This afternoon for instance, there is another panel discussion on macro-level ABMs with Syvain Barde, Andrea Roventini, and Alessio Moneta. Sadly, I cannot attend as it happens at the same time as our session. Yet, it is great to see that the field is developing - the success of the WEHIA conference has certainly contributed to this - and reaching out to the wider community in economics, beyond the immediate interacting-agent dynamics crowd assembled in the WEHIA.
April 10 2019 03:31:14.
EAEPE 2019 submission deadline extended
The submission deadlines for this year's EAEPE sessions have been extended until April 15, Monday next week. So the chance to submit a contribution is still there, both for our regular Complexity Economics session and for our special session on "Machine learning, AI, and Robotization: Effects on socio-economic systems and opportunities for economic analysis".
Incidentally, arstechnica is running a special piece on this exact topic, the social effects of AI and machine learning. Of course, you can't expect too much from a popular science article, but that said, it is a pretty comprehensive introduction. I like that it goes all the way to Deep Fakes and Generative Adversarial Networks at the end of the article.
March 28 2019 00:33:22.
EAEPE 2019 Sessions: "Machine learning, AI, and Robotization" and "Complexity Economics"
At this year's EAEPE conference, we will have a special session on "Machine learning, AI, and Robotization: Effects on socio-economic systems and opportunities for economic analysis", organized together with Alessandro Caiani, Andrea Roventini, and Magda Fontana. Machine learning, AI, and robotics are a very powerful tools that may go a very long way in transforming our economy, our society, and our academic system including economics - for the better or for the worse. We do in any case live in a very exciting time - so many new methods become available, so many new data sources, so many new concepts of analysis and also of intervention become feasible.
All this and more will be discussed in the special session. For details, see the call for papers for the special session on Machine Learning.
In addition, we will also have our regular session in Research Area [Q] - Economic Complexity. This research area was created in 2017 and participated for the first time in the conference in 2017 in Budapest. This year, it is going to happen for the third time. We had very inspiring discussions in the past years and are looking forward to again providing a space to discuss the role of complex systems in the economy.
See the call for papers for the sessions of Research Area [Q] - EconomicComplexity for details.
The submission deadline in both cases is next Monday, April 1st. Abstracts should be submitted in the online submission system.
September 26 2018 10:30:26.
CCS 2018 Satellite Meeting
This week, we will hold our CCS 2018 satellite meeting on "Trade runner 2049: Complexity, development, and the future of the economy" (again co-organized with Claudius Gräbner).
The title is, of course, a tribute to a recent movie combined with the idea that we are working to understand the future of the economy. Nevertheless, the range of talks will actually be quite diverse, not just about development economics.
I am very excited about our keynote, which will be given by Magda Fontana with a focus on the geographical distribution of novel and interdisciplinary research - a topic that researchers can relate to at a personal level.Update: The satellite meeting has been shifted to the afternoon session (Wednesday September 26 2018). The programme in detail:
14.30-16.00 |
Magda Fontana | University of Turin | Science, novelty and interdisciplinarity: topics, networks and geographical evolution. (See conference website) |
16.00-16.30 |
Coffee Break | ||
16.30-17.00 |
Paolo Barucca, Piero Mazzarisi, Daniele Tantari and Fabrizio Lillo | University College London | A dynamic network model with persistent links and node-specific latent variables, with an application to the interbank market. (See conference website) |
17.00-17.30 |
Jessica Ribas and Eli Hadad, Leonardo Fernando Cruz Basso, Pedro Schimit and Nizam Omar | Universidade Presbiteriana Mackenzie | A Case Study About Brazilian Inequality Income Using Agent-based Modelling and Simulation. (See conference website) |
17.30-18.00 |
Sabine Jeschonnek | Ohio State University at Lima | That Syncing Feeling - The Great Recession, US State Gross Domestic Product Fluctuations, and Industry Sectors. (See conference website) |
18.00-18.30 |
František Kalvas | University of West Bohemia in Pilsen | Experience in the Retirement Fund Problem. (See conference website) |
July 22 2018 02:29:28.
ZIP to NUTS code correspondence files for Albania and Serbia
When dealing with economic micro-data, a consistent separation in geographical regions is very useful. For much of Europe - the EU, EU candidate countries and EFTA countries - Eurostat's Nomenclature of Territorial Units for Statistics (NUTS) provides exactly this. What is especially useful if you have data that does not include NUTS codes but, for instance, addresses, are the postcode to NUTS correspondence tables provided by Eurostat. Of course, they are not entirely consistent and may require some cleaning. For instance for Luxemburg and Latvia, they include the country code into the postcode (""); for Montenegro, several ZIP codes are listed twice (a bit silly, especially since all of Montenegro maps into the same NUTS3 region).
More annoying, however, is that no correspondence files are provided as yet for Albania and for Serbia. For Albania, this is relatively straightforward to compile as both postal codes and NUTS regions are nicely aligned with the country's administrative divisions. Here is a postal code to NUTS code correspondence file for Albania in the same format as the ones provided for other countries by Eurostat. Here is how to build it:
Note that this compiles a short correspondence file with only the ZIP codes you actually have. The file below has all of them.# assume the dataset is a pandas data frame named df with a column ZIPCODEzipcodes = df.ZIPCODE.unique() zipToNUTS3 = {"10": "AL022", \ "15": "AL012", \ "20": "AL012", \ "25": "AL022", \ "30": "AL021", \ "33": "AL021", \ "34": "AL021", \ "35": "AL021", \ "40": "AL015", \ "43": "AL015", \ "44": "AL015", \ "45": "AL014", \ "46": "AL014", \ "47": "AL014", \ "50": "AL031", \ "53": "AL031", \ "54": "AL031", \ "60": "AL033", \ "63": "AL033", \ "64": "AL033", \ "70": "AL034", \ "73": "AL034", \ "74": "AL034", \ "80": "AL011", \ "83": "AL011", \ "84": "AL011", \ "85": "AL013", \ "86": "AL013", \ "87": "AL013", \ "90": "AL032", \ "93": "AL032", \ "94": "AL035", \ "97": "AL035"} outputfile = open("NUTS/pc_al_NUTS-2013.csv", "w") outputfile.write("CODE;NUTS_3\n")forzinzipcodes: outputfile.write("{0:s};{1:s}\n".format(z, zipToNUTS3[z[:2]])) outputfile.close()
For Serbia it is a bit more complicated and has to be pieced together from the postal codes (see here on the Serbian language wikipedia) and the NUTS regions for Serbia. The NUTS regions actually are aligned with the oblasts, see here. Building the correspondence file is therefore similar to the code for Albania above, just a bit longer. Oh, and here are general correspondence files for Albania and Serbia.
June 23 2018 21:09:46.
Democracy in Europe
Yesterday, in what could be described as a last-ditch effort to save polio from eradication, Italy's deputy prime minister and far-right populist Matteo Salvini came out as a vaccination denier. He said he believes vaccinations to be useless and harmful.
Salvini is clearly in a great position. He can shoot against the establishment from the second row while completely controling Italy's politics. Giuseppe Conte, the powerless prime minister, and Luigi Di Maio, who allows himself to mostly be treated like a child by Salvini, will certainly not stop him.
The European far right clearly learned their lessons from Donald Trump's approach to multi-media politics very well: 1. The truth really doesn't matter. 2. Tell everyone what they want to hear. Consistency doesn't matter either. 3. Claim to be some kind of anti-establishment figure. 4. Foment hatred against minorities. 5. Create as much outrage as you can. 6. Seek alliances with anyone who also doesn't care about the truth; vaccination deniers, Neo-Nazis, climate change deniers, young earth creationists, theocons, Putin apologists.
Of course, all this is not exactly new. We have gotten used to the political escapades the Le Pen family blesses us with every few years. Some may still remember Pim Fortuyn. Or maybe the scandal-ridden ÖVP-FPÖ government of Wolfgang Schüssel in Austria, something Sebastian Kurz seems intent on repeating with a bit of personality cult added. Germany, in turn, recently repopularized the term "Lügenpresse" that even made it to Trump's 2016 electoral campaign. Fallen into disuse after the defeat of Nazi-Germany in 1945, the term was resurrected first by the local xenophobic protest movement of Lutz Bachmann, a notorious lyer and petty criminal, then by various AfD politicians; while the CSU still avoids using the term directly, they certainly took a page out of Lutz Bachmann's and the AfD's playbooks.
Beyond these more recent movements that rode the wave of twitter and social media driven politics, some older and more stoic types of far right politicians have already succeeded in practically taking over teir countries. Now, armed with new ideas of how to make use of social media, they are about to chop away at their countries' democratic institutions. Jarosław Kaczyński and Victor Orbán are creating far-rightist autocracies in Poland and Hungary. Vladimir Putin has succeeded in building a right wing authoritarian state in Soviet style and with just a pinch of religious conservativism. His approach too, ableit different from Trump's and Salvini's bombastic twitter rants, is succeeding prodigiously. The attitudes of the Russian public are changing; they are becoming progressively conservative, religious, and anti-gay. Gay people and liberal activists were the first to suffer but they will not be the last. Meanwhile with regard to Turkey, nobody really knows what Recep Tayyip Erdoğan has in mind for the country; it appears to be some kind of theocracy. (He would honestly strike a much better caliph than al-Baghdadi.) In any case, he appears to be set to win tomorrow's elections.
While as of yet all is not lost, and while there are good strategies to counter the surge of the far right, recent developments warrant a look at the map. Ian Goldin and Chris Kutarna famously offered a strangely optimistic view of how democracy is spreading around the world with two maps showing the world's democracies in 1988 and 2015 on pages 32 and 35 of their recent book "Age of discovery". The message of the comparison is seems clear and obvious: Everything is fine; we are entering a golden age. Well, here are two different maps.
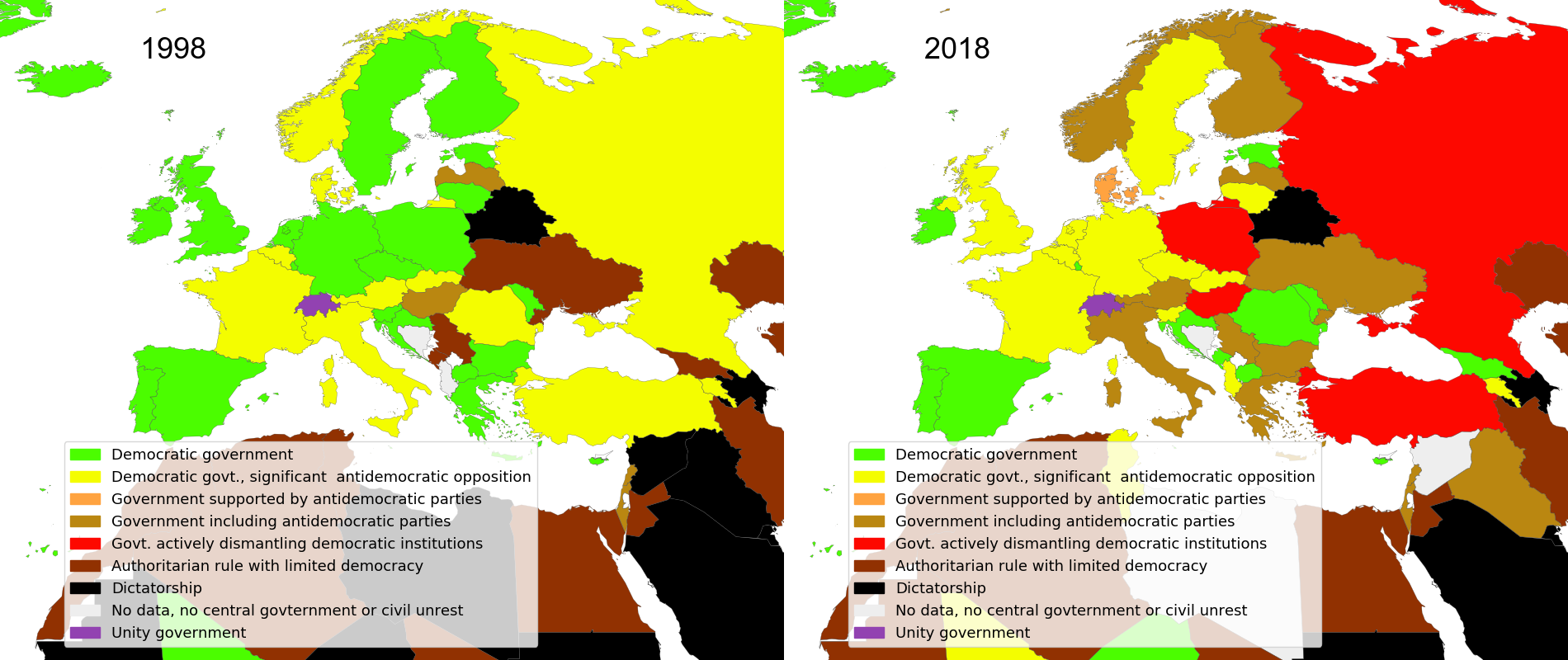
June 23 2018 18:52:27.
CCS 2018 Satellite Meeting on "Trade Runner 2049: Complexity, Development, and the Future of the Economy"
Together with Claudius Gräbner, we organized two very successful CCS satellite meetings in 2016 and 2017. I am very much looking forward to continuing this at the CCS conference in Thessaloniki in September. This year, we chose to place the focus on development and trade - hence the tongue-in-cheek title "Trade Runner 2049" - as well as machine learning and its challenges and potential for economics and the economy.
The abstract submission is still open, but the deadline is coming up rather soon - next week Tuesday, June 26. As always we are looking forward to receiving many inspiring and insightful papers and to a great satellite meeting in September. See the satellite meeting website for the call for papers and other details.
June 08 2018 02:02:43.
Economics LaTeX Bibliography (bibtex) styles
There are very many LaTeX bibliography styles out there. Most people use only a handful that are common in their field; some journals compile their own in order to avoid confusion and chaos. The various styles differ significalntly. No matter what kind of bibliography or citation layout you are looking for, most likely someone needed this before and has compiled a bibtex style file (bst). No matter how unusual a bibliography and citation layout you want, likely it already exists. So far so good.
Now you just have to find the bst that is to your liking. You can have a look around CTAN. If you have one of the more extensive LaTeX distributions installed, it likely comes with a great number of styles, just search your system for .bst files. And then you can try every one of them until you find what you need. Good luck with that; it is very tiresome.
Luckily there are a few comparisons out there, e.g. the one by Russ Lenth from the University of Iowa. (It is not the most extensive one but I always have trouble finding the others again.)
Sadly, nothing like this exists for economics packages. Until recently. Since I needed it a few months ago, here it comes.
A bit more explanation: Arne Henningsen (arnehe) has, a few years ago, thankfully, collected a few common bibtex styles used by economics journals. They can be found at CTAN and at Sourceforge or in your LaTeX distribution (depends on which one you have; texlive has it included). Also, see the website of the economtex project. Sadly, the project mostly comprises styles for fairly neoclassical journals, little in terms of the heterodox world. This may be because many heterodox journals are simply too small to maintain their own styles and rely on styles provided by the publishers or (as is the case for JoIE for instance) do not allow submission in LaTeX at all.
Specifically, the styles are- aer (AER)
- aertt (also AER?)
- agecon (Agricultural Economics)
- ajae (American Journal of Agricultural Economics)
- apecon (Applied Economics)
- cje (Canadian Journal of Economics)
- ecta (Econometrica)
- ecca (Economica)
- erae (European Review of Agricultural Economics)
- ier (International Economic Review)
- itaxpf (International Tax and Public Finance)
- jae (Journal of Applied Econometrics)
- jpe (Journal of Political Economy)
- jss2 (Journal of Statistical Software)
- oega (Österreichische Gesellschaft für Agrarökonomie)
- regstud (Regional Studies)
- tandfx (Taylor and Francis Reference Style X)
- worlddev (World Development)
\usepackage{natbib,har2nat} and \usepackage{ulem}.)
October 08 2017 00:14:08.
How to list most disk space consuming directories in UNIX/GNU/Linux
Yes, you can list files withls -l with any number of options and see large files in one directory. But what if you want to have a sum over what hard drive space everything in a directory occupies? This would be very helpful when cleanung up your hard disk, wouldn't it?
It turns out, this can be done (for the entries of the current directory) with du -sh *. But that generates an excessive amount of output, printing every single entry, no matter how small. And du does not sort.
But with a bit of effort, we can clean that up. Let's write a script which we call llama.sh (for list large and massive agglomerations):
#!/bin/bash
llama() {
du -sh "$@" | grep -e [0-9][0-9][0-9]G$'\t' | sort -r &&\
du -sh "$@" | grep -e ^[0-9][0-9]G$'\t' | sort -r &&\
du -sh "$@" | grep -e ^[0-9]G$'\t' | sort -r &&\
du -sh "$@" | grep -e [0-9][0-9][0-9]M$'\t'|sort -r;
}
llama "$@"
chmod +x llama.sh
./llama.sh *
source llama.sh
llama.sh *
llama.sh /*
746G /home
28G /mnt
15G /usr
8.3G /var
169M /boot
161M /opt
STDERR to /dev/null in order to actually get to see your output in a concise form without thousands of errors:
llama.sh /* 2>/dev/null
September 21 2017 09:34:17.
CCS 2017 Satellite Meeting
Today, finally, is the day of our CCS 2017 satellite meeting on "Institutions, Industry Structure, Evolution - Complexity Approaches to Economics" (co-organized with Claudius Gräbner). In spite of a few last minute changes, we now have a great programme with a keynote by Hyejin Youn from Northwestern University, Chicago and many interesting contributions by, among others, Stojan Davidovic, Francesca Lipari, Neave O'Cleary, Ling Feng, and Carlos Perez. See the programme in pdf format here; details can be found on the website.May 27 2017 20:48:34.
CCS Satellite Meeting on "Institutions, Industry Structure, Evolution - Complexity Approaches to Economics"
We, Claudius Gräbner and me, are again organizing a Satellite Meeting of the Conference on Complex Systems 2017 in Cancun. The broad topic is again complexity economics, but we are putting a focus on aspects of institutionalist economics, industrial organization and and evolutionary approaches. For details, see the call on the website of the satellite. As one of the more important interdisciplinary conferences on complex systems the gatheing, organized annually by the Complex Systems Society is of immense importance to complexity economics. With a moderate but increasing number of economists attending the CCS every year, we can hope that it contributes greatly to spreading the use of network theory, agent-based modelling, simulation and data sciences in general in economics. What is more, complexity economics complements the perspective of institutional economics, evolutionary economics, and industrial economics (to name a few) neatly.May 21 2017 21:22:43.
R and Stata
Though R is not only open-source but arguably also the more powerful language for statistical computing, many statisticians and especially econometricians continue to use and teach Stata. One reason is that they were first introduced to Stata, giving rise to a classical case of a path dependent development. When I found myself in exactly that situation two years ago, I collected a number of R commands and their Stata equivalents (or vice versa) into a pdf. Maybe, it will be of use to some of you.May 03 2017 06:07:20.
EAEPE Research Area for Complexity Economics established
The EAEPE (European Association for Evolutionary Political Economics) has established a new Research Area [Q] for complexity economics. Together with Magda Fontana from Torino and Wolfram Elsner from Bremen, I will serve as Research Area Coordinator for this branch.
It is our hope to promote complexity economics, to bring more scholars working in this exciting and promising field into the EAEPE, and to encourage cooperation with scholare in existing Research Areas such as simulation (RA [S]), networks (RA [X]), technological change (RA [D]).
Research Area [Q] will participate already in the annual conference 2017 in Budapest. Please see the research area specific call for papers.
May 02 2017 21:21:19.
Stack conversion for image files
Suppose, you need to convert a large number of images and do not want to do it by hand. This can be done with simple shell scripts using Imagemagick'sconvert
Say you want to convert a stack of files from png to jpg (replace pattern appropriately):
... or the other way around (jpg to png). And maybe you also want to replace black areas in those files by transparent areas at the same time (may help make presentations look more fancy):#!/bin/bashforfin`ls *.png`dofnew=`echo $f|cut -d. -f1` fnew=$fnew".jpg" convert $f -background white -flatten $fnewdone
Or, maybe you just wanted to rename a stack of files (replace filename pattern and text_to_replace and replacement_text patterns appropriately)#!/bin/bashforfin`ls *.jpg`dofnew=`echo $f| cut -d. -f1` fnew=$fnew.png convert $f -transparent black $fnewdone
#!/bin/bashforfin`ls filename_pattern*.pdf`donf=$(echo $f | sed 's/text_to_replace/replacement_text/') mv $f $nfdone
May 02 2017 04:15:56.
How to join pdf files with a certain filename pattern
This can be done with a simple python script like so. Works with Linux, perhaps also with BSD, Mac, and, less likely, Windows:#!/usr/bin/env pythonimportglob,os,sys# Import the appropriate pyPDF for python2 or python3 respectivelytry:frompyPdfimportPdfFileReader, PdfFileWriterexcept:fromPyPDF2importPdfFileReader, PdfFileWriter# Attempt to apply pattern supplied as agrument and generate list of pdfsiflen(sys.argv)>1: pdflist=glob.glob(sys.argv[1]) print(pdflist) print(sys.argv[1])else: pdflist=glob.glob("*.pdf") print(pdflist) print("no pattern given, you may give a pattern for pdfs to include,\ keep in mind to escape * etc. like so:") print(" python2 joinpdf.py \"\*.pdf\"") print("or:") print(" python2 joinpdf.py \"pattern-\*-pattern.pdf\"") pdflist.sort() output = PdfFileWriter()forinpdflist:# Read pdf files one by one and collect all pages into outputinput = PdfFileReader(open(pdf, "rb"))foriinrange(input.getNumPages()): page = input.getPage(i) output.addPage(page)# Write joined pdfoutputStream = open("joined.pdf", "wb") output.write(outputStream) outputStream.close()
May 01 2017 11:56:27.
How to run a shell script in a loop until it succeeds
I admit, there is only a limited number of use cases for this. But it may sometimes happen that you want to run a script in a loop again and again until it succeeds. Say, you are on an unstable network and are trying to obtain an IP usingdhcpcd:
#!/bin/bash false exitcode=$?while[[ $exitcode -ne 0 ]]doecho $exitcode dhcpcd wlan0 exitcode=$?done